DEX文件解析
对Dex进行分析之前,首先要知道它是什么,为什么值得我们去分析。由于是初学,对于其中部分内容描述可能并不是特别准确,仅建立在个人的理解基础上。如果有不同意见,欢迎在issues上讨论。
classes.dex文件中包含了apk的可执行代码。之前在对Apk文件进行简单的分析的时候,知道了java生成的代码,会编译生成.dex文件。- DEX文件中包含了许多的逻辑信息,通过对它的分析,我们可以尝试逆向得到编写的源码。
1 DEX文件整体结构
下图是一幅对Dex中各部分详细分析的图片,来源
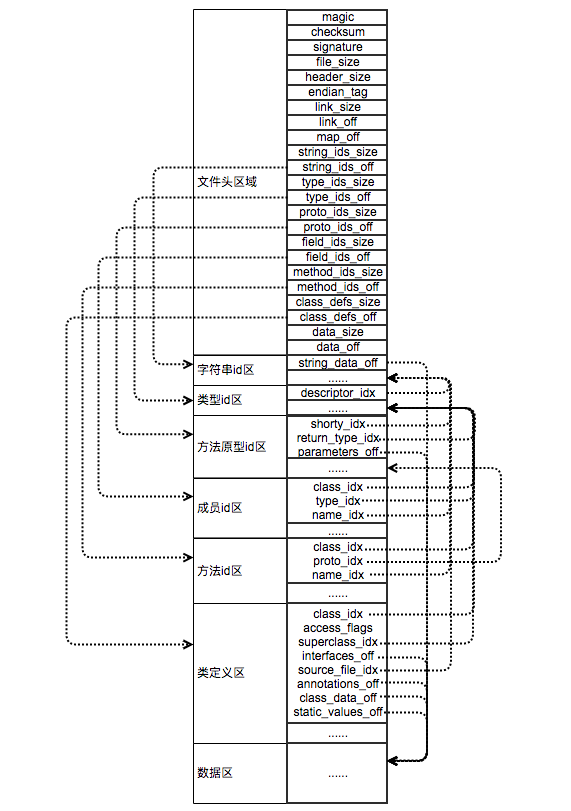
简单区分的话,则可以划分为以下几个部分:

文件头,索引区,数据区,接下来就是对这几个部分的逐步分析过程
2 Dex解析过程
2.1 文件头 Dexheader
可以说理解了Dexheader,然后知道一点点编译原理,对于我们理解索引区可以有很大的帮助。
1 | /* |
以上是dexheader.h中DexHeader结构体,可以看到具体有些什么信息。对于其中各部分的意义已经标注,下表则是我个人对于其中部分结构的理解:
| 名称 | 意义 |
|---|---|
| magic | 描述了文件的类型以及版本 |
| checksum | 整个文件检验和,除掉checksum和signature |
| signature | 文件的签名信息,同样不包括checksum和signature |
| filesize | 整个文件一共有多大 |
| headerSize | DexHeader有多大 |
| endiantag | 文件序标签,表明是大端存储还是小端存储 |
| link | 链接段 |
| map | 这是在数据区的内容,可能在内存中读取这一块完成对Dex文件的解析 |
| stringid | 是.dex文件中所有的字符串的索引 |
| typeid | 代码中的所有数据类型信息 |
| proto | 方法原型 |
| field | 字段(域)区 |
| method | 方法区 |
| class | 类区 |
| data | 数据区 |
对于这部分解析的代码如下:
1 | self.header_data = { |
2.2 DexMapList
1 | DexMaplist : { |
首先是MapList的个数n,后面紧接着n个大小为12个DexMapItem结构体。
类型有以下几种:
1 | /* map item type codes */ |
根据map字段,我们可以知道每个类型字段的个数,起始偏移
2.3 DexStringId
1 | DexStringId : { |
在Dexhead中,得到DexStringId的起始偏移后和个数后,我们可以知道每一个string的数据区中起始偏移,而dex中的string使用的是MUTF-8数据结构。对于DexStringId的解析代码如下:
1 | # 对DexStringID的解析 |
解析结果如下:
1 | strings_id个数: 16 |
2.4 DexTypeID
1 | DexTypeId : { |
解析代码:
1 | # 对DexTypeId 的解析 |
结果:
1 | type_id个数: 7 |
2.5 DexProtoID
1 | DexProtoID : { |
解析代码如下:
1 | # 对DexProtoId的解析 |
结果:
1 | proto_id个数为: 4 |
2.6 DexFieldID
1 | DexFieldID : { |
解析代码:
1 | # 对 DexFieldId的解析,字段 |
结果:
1 | Field_id个数为: 1 |
2.7 DexMethodID
1 | DexMethodId : { |
解析代码:
1 | # 对 DexMethodId的解析 |
结果:
1 | Method 个数为5 |
2.8 DexClassID
1 | DexClassId : { |
解析代码:
仅仅解析到了每个字段的偏移,后面的内容以后有机会在详细整理,整理上结构梳理过程
1 | def get_class_defs(self): |
解析结果:
1 | class_def_id个数为: 1 |
3 总结
花了几天,重新梳理了一遍Dex文件,大概是清楚了中间的一个流程,但是在后续学习中还有许多地方值得继续深入学习的,比如:
- 为什么需要DexMapList数据结构来做一个map
- 在
classDef后面的数据区开始的位置存储的是什么 - 签名验证的整个过程是什么样的
- MultiDex的怎么分析
- opcode解析过程理解
参考资料
[1] Android 软件安全权威指南
[2] 官方文档