ARM 汇编语言学习
在之前翻译《x86汇编语言导论》的时候,大致上重新梳理了一下汇编的语言的思想。但是这几天开始学习Android NDK的时候还是对arm上的指令集一知半解,所以决定也做一个简单的梳理,参考资料基于AZERIA lab的《Introduction to arm assembly basics》系列文章。下面开始吧
1 ARM 汇编语言简介
指令集架构:
- Inter是一个CISC(complex instruction set computing)复杂指令集处理器,具有功能更加庞大,更加丰富的指令集。以及更加复杂的操作和寻址方式,且寄存器更少。基于栈架构。
- arm是一个RISC(Reduced instruction set computing)精简指令集处理器,寄存器数量多,指令集简单,基于寄存器架构,使用load/store结构访问存储器。
- RISC 比之于CISC主要是力图保持各opcode的长度相等,在最开始的时候,所有指令的长度都是4个字节的。
- RISC指令可以更快的被执行,减少了每一条指令占用CPU的时钟周期,但它较少的指令增加了编译器的复杂性
- arm指令集又分为三类,ARM模式,Thumb模式,ARM64模式
在arm中,由于只处理寄存器中的数据,且使用load/store结构访问存储器,所以如果我们需要增加某一个内存地址中的值的时候,至少使用三种类型的指令(load从内存中取值存入寄存器,add加法指令进行加法运算,store又将值从寄存器存到内存种)

arm指令集又不同的版本,以上的表中对应的是arm指令集版本和处理器版本之间的映射关系
当我们编写好了汇编之后,同样需要汇编,链接,然后执行
1 | $ as program.s -o program.o # 汇编 |
2 ARM数据类型和寄存器
2.1 数据类型
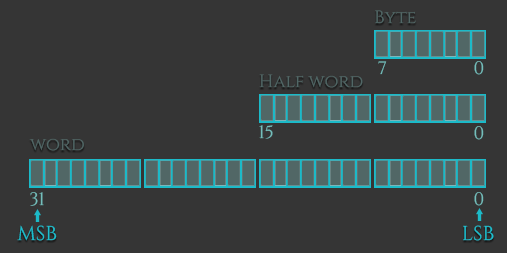
ARM中的数据同样可分为有符号数和无符号数两种,按存储空间又可分为字,半字,字节三种类型,1个字节8位,一个半字16位,一个字32位。
下面是数据相关指令集:
1 | ldr # Load Word |
2.2 字节序
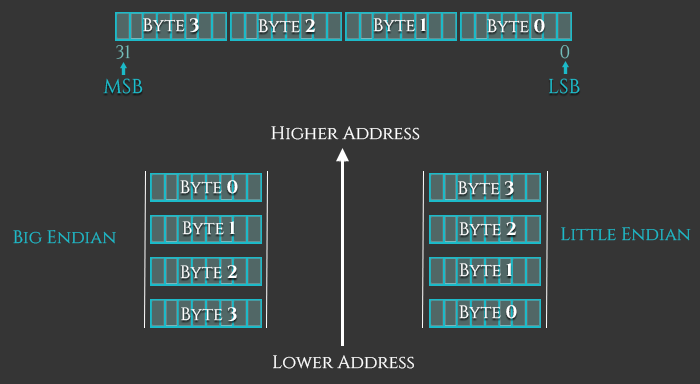
内存中的字节序一般有两种,小端(Little-Endian,LE)字节序,和大端(Big_endian,BE)字节序,x86使用的是小端字节序,arm在第三版之前是大端字节序,但是在之后可以设置切换字节序了。在程序状态寄存器(CPSR)的第9位E(ndian)位控制.
2.3 ARM 寄存器
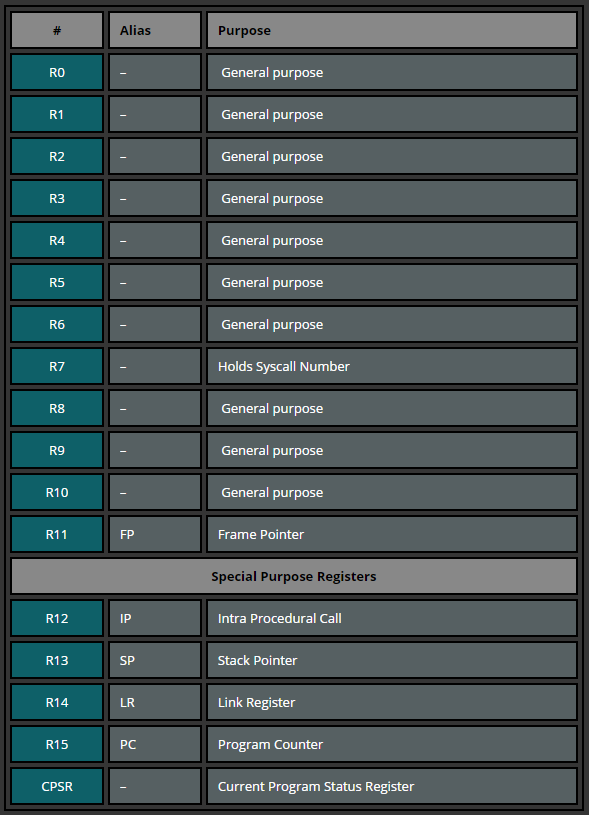
ARM寄存器的数量取决于ARM的版本,根据ARM参考手册,我们可以知道,有30个32位的通用寄存器(除ARMv6-M和ARMv7-M的处理器之外)。在这里,我们先关注在任何模式下都能访问到的寄存器R0-R15。这16个寄存器可以被分为两组,一种是通用寄存器,一种是有这特殊用途的寄存器。
下面这张图是ARM寄存器和intel寄存器的对比
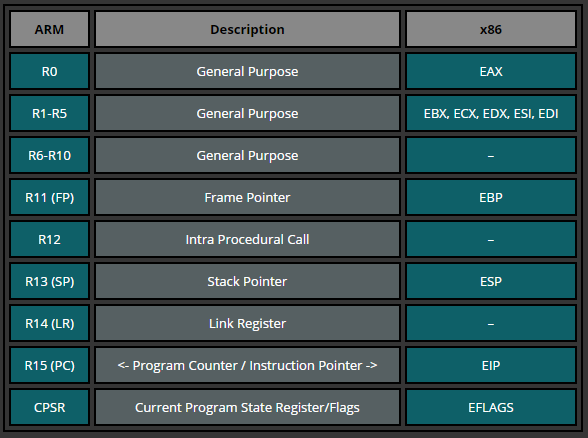
可以看到,从前到后,依次是累加器,基址寄存器,计数器,数据寄存器,栈帧,栈低,IP,状态寄存器,当然,这么将是为了便于记忆,到现在好像每个寄存器的功能已经不再唯一。
R0-R12通常存放在运算过程中产生的临时的数据,指针等等。此外,在ARM的调用约定中规定,参数的前4个存储在R0-R3中,之后的存储在栈中。
R0用来传递返回值。
FP(R11)用来存储系统函数调用值,也相当于是函数的栈帧
SP(R13)寄存器存储栈顶。
LR(R14)寄存器用来存储函数的返回地址
PC(R15) 寄存器会自动增加执行指令的大小,在ARM状态下一直都是4个字节,在Thumb模式下,大小始终为2个字节。当执行分支转移指令的时候,PC会保存目的地址?在执行期间,ARM模式下PC存储的当前指令的地址+8(下面的第二条指令地址),Thumb模式下存储当前指令的地址+4,和x86的PC始终存储下一条将要执行的指令地址是不一样的。
1
2
3
4
5
6
7
8.section .text
.global _start
_start:
mov r0, pc
mov r1, #2
add r2, r1, r1
bkpt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$r0 0x00000000 $r1 0x00000000 $r2 0x00000000 $r3 0x00000000
$r4 0x00000000 $r5 0x00000000 $r6 0x00000000 $r7 0x00000000
$r8 0x00000000 $r9 0x00000000 $r10 0x00000000 $r11 0x00000000
$r12 0x00000000 $sp 0xbefff7e0 $lr 0x00000000 $pc 0x00008054
$cpsr 0x00000010
0x8054 <_start> mov r0, pc <- $pc
0x8058 <_start+4> mov r0, #2
0x805c <_start+8> add r1, r0, r0
0x8060 <_start+12> bkpt 0x0000
0x8064 andeq r1, r0, r1, asr #10
0x8068 cmnvs r5, r0, lsl #2
0x806c tsteq r0, r2, ror #18
0x8070 andeq r0, r0, r11
0x8074 tsteq r8, r6, lsl #6在最开始的时候,pc存放的是当前将要取指的指令地址
0x8054在运行第一条指令的时候,期望的输出应该是
0x8054,但实际上,输出的是0x805c。由于老版本的ARM处理器总是获取当前已经执行的指令的后两条指令的地址,ARM保留这一特性的原因也是为了保证和早期处理器的兼容性
CSPR current program status register 当前程序状态寄存器

对应的含义如下:
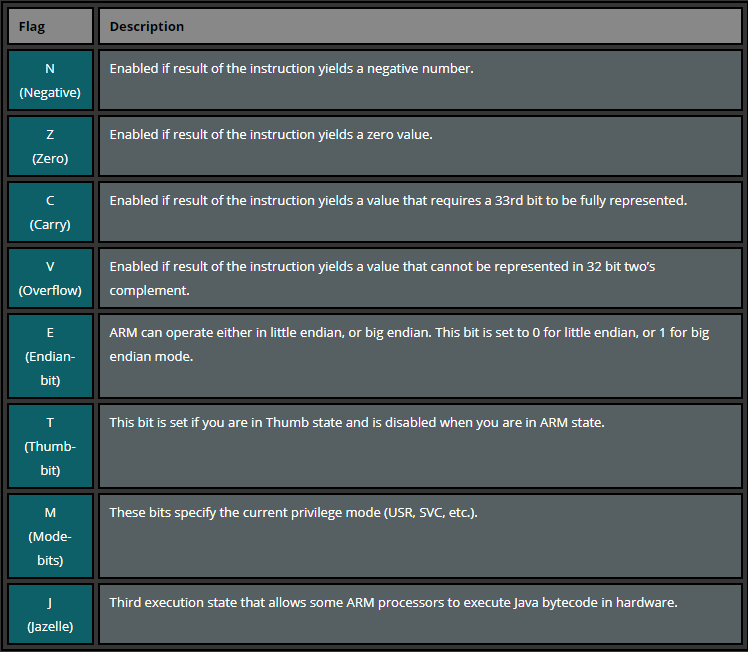
1
2
3cmp r1, r0; 1-2 = -1 N = 1
cmp r1, r0; 2-2 = 0 Z = 1
cmp r1, r0; 4-2 = 2 C = 1 (减法是补码计算,实际上是 [4]补 + [-2]补,有进位)N - 计算结果为负数
Z - 计算结果为0
C - 计算结果有进位
- 如果计算加法结果大于$2^{32}$
- 计算减法结果为非负数
- 在赋值操作或者逻辑指令中,进行内联桶式移位操作的结果
V - 计算结果有溢出
- 当加法/减法/比较指令结果大于等于$2^{31}$或者小于等于$-2^{31}$会溢出
3 ARM 指令集
3.1 ARM和Thumb
ARM有两种主要的状态,ARM和Thumb模式,两种状态在所有的权限下都可以运行。
在ARM状态下指令集都是32位的,而Thumb模式下是16位或者32位的。需要知道在哪些地方使用Thumb代替ARM。
引入Thumb增强指令集之后,还需要了解到自己的设备支持的是哪一种,并进行相应的调整。
ARM和Thumb的不同:
- 条件执行: ARM状态下所有的指令都支持条件执行,某些ARM处理器版本允许使用IT指令在Thumb中有条件执行 ,条件执行会有更高的代码密度,因为它减少了要执行的指令数量并减少了昂贵的分支指令数量。
- 32位的ARM和Thumb指令集:Thumb指令集有一个.w后缀
- ARM模式可以使用桶位移指令:它可以用于将多个指令缩小为1个,例如,我们可以使用一条指令
mov R1, R0, R0, LSL#1来代替使用两个指令执行一次乘法(将寄存器里的数乘以2并将它存储到另外一个寄存器
切换处理器的执行状态以下两个条件必须满足:
我们可以使用分支指令BX(分支和交换)或BLX(分支,链接和交换)并将目标寄存器的最低有效位设置为1。可以通过添加1的偏移来实现,如0x5530+ 1。这不会因为指令要么是2字节,要么是4字节对齐而产生对齐问题。因为处理器将忽略最低有效位。
如果当前程序状态寄存器中的T位置1,处于Thumb模式。
3.2 ARM指令集介绍
通用模板如下
1 | MNEMONIC{S}{condition} {Rd}, Operand1, Operand2 |
例子:
1 | ADD R0, R1, R2 |
逻辑左移和算数左移右边补位都是0,逻辑右移左边添0,算数右移右边添符号位
以下是最常用的指令

4 内存指令:加载和存储
ARM 使用了load-store模块来进行内存的访问,这就意味着,只有lad/store(LDR 和 STR)指令能够进行内存访问。而在x86指令集中,大多数的指令都是可以直接操作内存中的数据的。在ARM中,数据在被操作之前,必须首先从内存移入寄存器。这就意味着,在ARM中如果想要一个物理地址上增加一个32位的数据的时候,必须使用三种类型的指令(load/increment/store),首先将物理内存中的数据加载进入寄存器,然后使用寄存器进行加法运算,最后将数据从寄存器存回内存地址。
下面是几个示例,使用了三种基本偏移形式,每个偏移形式都用三种不同的寻址模式表示。对于每个示例,我们将借助不同的LDR/STR偏移形式, 并使用含义相同汇编代码让问题简化。
偏移形式:将立即数作为偏移/将寄存器作为偏移/将移位寄存器作为偏移
寻址模式:偏移寻址
寻址模式:先索引寻址
寻址模式:后索引寻址
4.1 基本示例

通常情况下,使用LDR将内存数据加载到寄存器中,使用STR将寄存器中的数据存储到内存地址中
1 | LDR R2, [R0] @ [R0] - origin address is the value found in R0. |
在汇编程序中是这样:
1 | .data /* the .data section is dynamically created and its addresses cannot be easily predicted */ |
下面是整个过程:
如果使用调试器调试的话,代码是下面这样:
1 | gef> disassemble _start |
最开始的两个指令被转换成了[pc, #12]。这是PC相对寻址,因为我们使用了地址标签,编辑器会自动计算文本池中指定标签的位置(PC + 12)。在我们的例子中,文本池的位置在PC指令的三条有效指令之后(PC指向当前执行指令地址后面的第二个)。

4.1.1 偏移模式:立即数作为偏移寻址
1 | STR Ra, [Rb, imm] |
这里我们使用一个立即数(整数)作为偏移量。这个值通过与基址寄存器(下面的例子中的R1)相加或相减来访问数据。它在编译时为已知的偏移量。
1 | .data |
注意基址寄存器什么时候变/不变,以及增加的大小。
offset address mod :
str r2, [r1, #2]r1存的值+2作为地址,取数据传递给r2,r1不变pre-indexed address mod:
str r2, [r1, #4]!r1的值+4作为地址,取数据传递给r2,r1 + 4post-indexed address mod:
ldr r3, [r1], #4r1存的值作为地址,取其中的数传递给r3,然后r1+4
4.1.2 偏移模式: 寄存器的值作为偏移地址
1 | STR Ra, [Rb, Rc] |
这种偏移模式将寄存器的值作为偏移量。如果我们准备访问一个正在运行时计算索引的数组,可以使用这种偏移模式。
1 | .data |
offset address mode:
str r2, [r1, r2]r1存的值加r2存的值作为地址,将r2中的值存进去,r1值不变pre-indexed address mode:
str r2, [r1, r2]!r1存的值加r2存的值作为地址,将r2中的值存进去,r1 = r1 + r2post-indexed address mode:
ldr r3, [r1], r2r1存的值作为地址,然后将r3存入,然后r1 = r1 + r2
4.1.3 偏移模式,使用移位寄存器作为偏移
1 | LDR Ra, [Rb, Rc, <shifter>] |
Rb是基址寄存器,Rc是立即数偏移或者是寄存器存储的立即数,<shifter>用于左右移位。常用于循环遍历数组
1 | .data |
offset address mode:
str r2, [r1, r2, LSL#2]r2存的值存入r1 + r2 * 4,下图是完整的示例: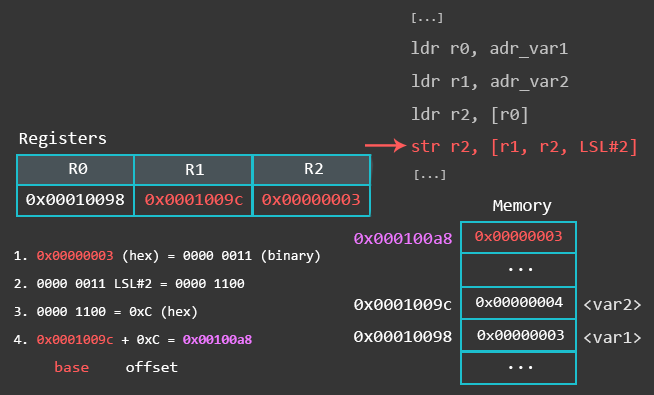
pre-indexed address mode:
str r2, [r1, r2, LSL#2]!r2存的值存入r1 + r2 * 4,然后r1的值更新为r1 + (r2 << 2)post-indexed address mode: ldr r3, [r1], r2, LSL#2 r1值作为地址,取值存放在r3,然后r1的值更新为r1 + (r2 << 2)
4.1.4 总结
记住LDR/STR用到的三种偏移模式
- offset mode uses an immediate as offset
ldr r3, [r1, #4] - offset mode uses a register as offset
ldr r3, [r1, r2] - offset mode uses a scaled register as offset
ldr r3, [r1, r2, LSL#2]
记住LDR/STR中不同的寻址模式
If there is a
!, it’s prefix address mode1
2
3ldr r3, [r1, #4]!
ldr r3, [r1, r2]!
ldr r3, [r1, r2, LSL#2]!If the base register is in brackets by itself, it’s postfix address mode
1
2
3ldr r3, [r1], #4
ldr r3, [r1], r2
ldr r3, [r1], r2, LSL#2Anything else is offset address mode.
1
2
3ldr r3, [r1, #4]
ldr r3, [r1, r2]
ldr r3, [r1, r2, LSL#2]
4.2 LDR 用于PC相对寻址
LDR 是唯一一个用于将内存中的数据载入寄存器(load data to register)的指令。而有时候会看到以下语法:
1 | .section .text |
这些指令被称为伪指令,我们可以使用这语法来引用 文本 池中的数据。文本池和代码段位于同一段内存区域(因为文本池也是代码段的一部分),常用于存储常量,字符串或者偏移量,在上面的例子中,使用了伪指令来引用一个函数的偏移量, 并用一个指令将一个32位常量移到一个寄存器中。 为什么我们有时需要使用这种语法来使用一个指令将32位常量移到一个的寄存器中呢,这是因为ARM一次 只能加载一个8位的值。什么?要理解为什么,你需要知道ARM上的立即数是如何处理的。
4.3 ARM中立即数的使用
将立即数载入ARM寄存器不像在x86上那样简单。我们能使用的立即数是有限制的。 另外还有一些窍门可以用来绕过这些限制。
我们知道,每一条ARM指令都是32位,所有的指令都是可以按照所选择的条件码条件执行的。一共有16种可供选择的条件码 ,一个条件码占4位,然后我们需要2位用于表示目标寄存器,2位用于表示第一操作数,1位用于设置状态标志位,再加上其他情况下我们可能需要使用的各种位数(例如实际操作码)。关键点在于:在将地址分配给指令类型,寄存器和其他字段之后,立即值只剩下12位,只能表示4096个不同的数。
但是更多的是,这12位并不是全都用来表示一个整数,而是将它分出8位用于表示任何8位的数(n),范围是0-255,以及一个用于循环位的4位数(r),在0到30之间以2为步长,这以为着一个立即数由以下公式给出$v = n\ ror\ 2*r$ 用另一句话说唯一有效的立即数是循环位移的位(可以减少以偶数旋转的字节的值)
1 | Valid values: |
这样的结果就是不可能一次加载完完整的32位地址,我们可以选择以下两个选项来绕过这个限制:
- 用较小的数来构造比较大的数
- 不使用
MOV r0, #511 - 将511拆成两部分
MOV r0, #256和ADD r0, #255
- 不使用
- 使用一个加载的构造形式
ldr r1, =value,汇编程序会很乐意转换为MOV或者是一个PC相对地址的load指令(在不能转换为mov的时候)- LDR r1, =511
在我们使用load加载一个无效的立即数的时候,汇编器会报错。如果我们想要将511加载到r0中:
1 | .section .text |
5 载入/存储多个值
有时候一次加载或者存储多个值会更有效率。因此我们会使用LDM(load multiple)指令和STM(store multiple)指令,这些指令有一些在访问初始地址方式上有所不同。下面是我们在本节中将会使用的代码.
1 | .data |
开始前,请记住.word指向了一个32位共计4字节的数据(内存)区块,这对于理解代码中的偏移很重要。程序中包含了.data区段,在这里我们开辟了一个有5个元素的空数组array_buffer,我们将使用它作为可写存储位置来存储数据 。.text段包含了由内存操作指令构成的代码,和一个包含了两个标签的只读数据池,其中一个标签规定了一个具有7个元素的数组,另外一个链接着.text区段和.data区段,我们可以用它访问.data区段的array_buffer。
1 | adr r0, words+12 /* address of words[3] -> r0 */ |
我们使用adr指令(和ldr取物理地址不同,adr取指令取的是基于PC指令的相对偏移,位置无关)来获取第四个(words[3])数据的地址,然后存入R0,我们指向数组的中间是因为我们将从那向前或者向后进行操作。
r0现在存储着word[3]的地址,假设它是0x80B8,这就意味着,我们数组的开始word[0]的地址是 0x80AC(0x80B8 - 0xC)
1 | gef> x/7w 0x00080AC |
我们用 array_buff数组的第一个( (array_buff[0] )和第三个元素( array_buff[2] )的地址来分别填充R1和R2。一旦地址被获取,我们就能操作他们了
1 | ldr r1, array_buff_bridge /* address of array_buff[0] -> r1 */ |
1 | gef> info register r1 r2 //用于获取寄存器的值 |
下一条指令使用LDM从r0指向的内存中取两个字的数据放入寄存器。因此我们早就将R0指向word[3],因此word[3]的值会被存入R4,word[4]的值会被存入R[5]
1 | ldm r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */ |
我们使用了一条指令加载了多个(2个数据块),使得 r4 = 0x03, r5 = 0x04,注意LDM的源/目的和LDR是不一样的,LDM src,dest
1 | gef> info registers r4 r5 |
下面是使用STM将多个值写入内存。STM指令将R4, R5寄存器的值0x3和0x4存入R1指向的内存空间中。由于之前R1指向的是array_buf的第一个元素,所以现在array_buff[0] = 0x00000003 array_buff[1] = 0x00000004.,除特殊情况外,LDM和STM操作步长为4个字节。
1 | stm r1, {r4, r5} |
1 | gef> x/2w 0x000100D0 |
如前面说述,LDM和STM有多种不同的使用形式。而具体使用哪一种形式是由指令的后缀指定的。这个示例列出了后缀 的几种不同的形式:-IA( increase after ) -IB( increase before),-DA( decrease after )-DB( decrease before ),这几种形式不同之处在于他们访问第一个操作数的时候指定内存的方式,实际上LDM和LDMIA相同,每一次加载之后,地址指针都会自己增加从而指向下一个将要被载入的元素。用这种方式我么能从第一个操作数(存储源地址的寄存器)指定的内存地址中获取了顺序(正向)数据加载
1 | ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03, words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */ |
LDMIB首相将源地址增加四个字节然后执行第一次加载,这种方式下,我们仍然可以顺序加载数据,但是第一个元素的地址与源地址有4个字节的偏移。这就是为什么在实例中,要通过LDMIB指令从内存中加载到R4中的第一个元素是words[4]而不是R0指向的words[3]
1 | ldmib r0, {r4-r6} /* words[4] -> r4 = 0x04; words[5] -> r5 = 0x05; words[6] -> r6 = 0x06 */ |
1 | gef> x/3w 0x100D4 |
当我们使用LDMDA的时候,所有的操作都是向后进行的。R0指向words[3],当加载开始的时候,我们将向后移动,然后将word[3].word[2],word[1]加载到r6,r5,r4之中。寄存器同样也是向后加载的,所以当指令完成的时候有: R6 = 0x00000003, R5 = 0x00000002, R4 = 0x00000001. 之所以是这样,是因为在每次加载之后,我们都会减小源地址。寄存器反向载入则是由于我们减少了内存地址之后,所对应的寄存器的编号值也跟着下降了,因为它需要遵守更高的地址使用更高的寄存器编号这一约定,查看LDMIA的示例,我们首先加载较低的寄存器,然后再加载较高的寄存器,因为它的源地址增加了
1 | ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2] -> r5 = 0x02; words[1] -> r4 = 0x01 */ |
1 | gef> info register r4 r5 r6 |
先降低地址,然后载入多个值
1 | ldmdb r0, {r4-r6} /* words[2] -> r6 = 0x02; words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */ |
1 | gef> info register r4 r5 r6 |
存储值然后降低地址
1 | stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02; r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */ |
1 | gef> x/3w 0x100D0 |
降低地址,然后存储值
1 | stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00; */ |
1 | gef> x/2w 0x100D0 |
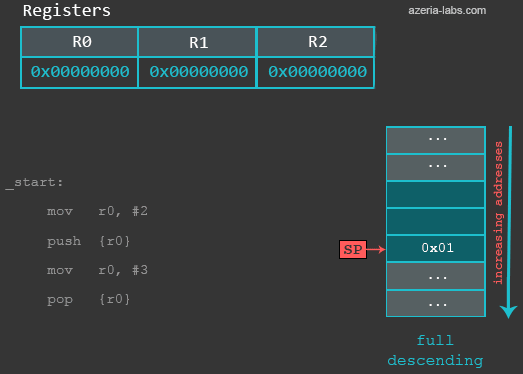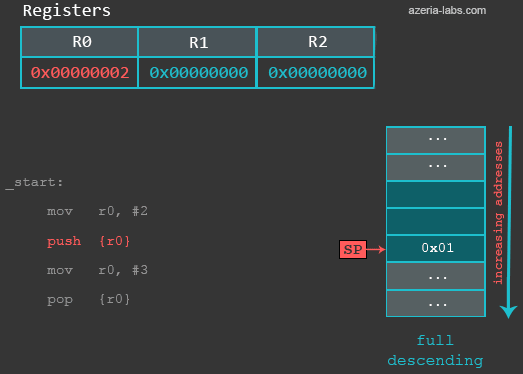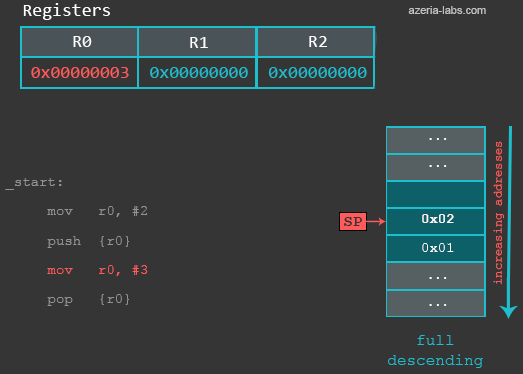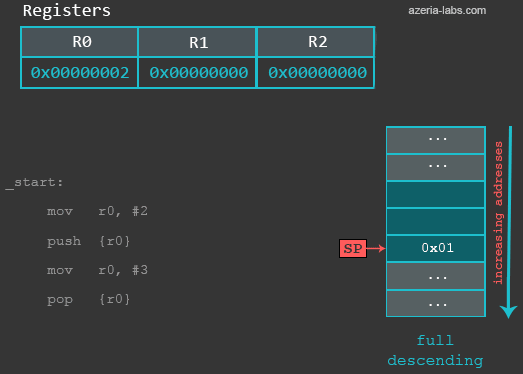
6 出栈和入栈
进程中有一块使用着的内存区域叫做栈,栈指针(sp)是一个寄存器,再正常情况下,它总是指向内存区域中的一个地址。应用程序通常使用栈作为临时的数据存储区域,在x86中,我们使用push和pop从栈中加载和存储,而在ARM中,我们也可以使用这两个指令。
当我们PUSH数据到一个下降栈的时候,会有以下的操作:
- SP寄存器中存储的地址-4
- 数据会存储到sp所指向的新地址
当从栈中POP数据的时候,会有以下的操作:
- 从当前SP所指向的内存中取出数据,然后传递给一个寄存器
- SP寄存器中存储的地址+4
在下面的例子中,会使用PUSH/POP 以及 LDMIA/STMDB
1 | .text |
反汇编之后:
1 | 00008054 <_start>: |
可以看到,LDMIA指令和STMDB指令也被转换为PUSH和POP指令了。这是因为 PUSH 是STMDB sp!的同义词,而POP则是LDMIA sp!的同义词
7 ARM 条件执行指令 && Thumb模式下的条件执行 && 分支指令
在讨论CPSR寄存器的时候,我们已经简要的提到了以下有关条件执行相关的知识。我么能使用条件指令来控制程序运行时的流程,一般条件下是通过跳转(分支)或者仅仅在满足某些条件的时候执行某些指令来控制程序的流程,该条件被描述为CPSR寄存器中特定的状态位。这些状态位会根据某些指令的结果不断的更改,例如,当我们在比较两个数的大小,并且他们两个的大小相等,我们触发了 ZERO bit (Z = 1),因为在底层挥发生b - a = 0,在这种情况下,我们会使用EQual指令。如果第一个数字更大,我么那会有一个(Great Than)的条件,相对立的有Low Than。下面列出了常用的条件,以及他们影响的CPSR寄存器的条件位:
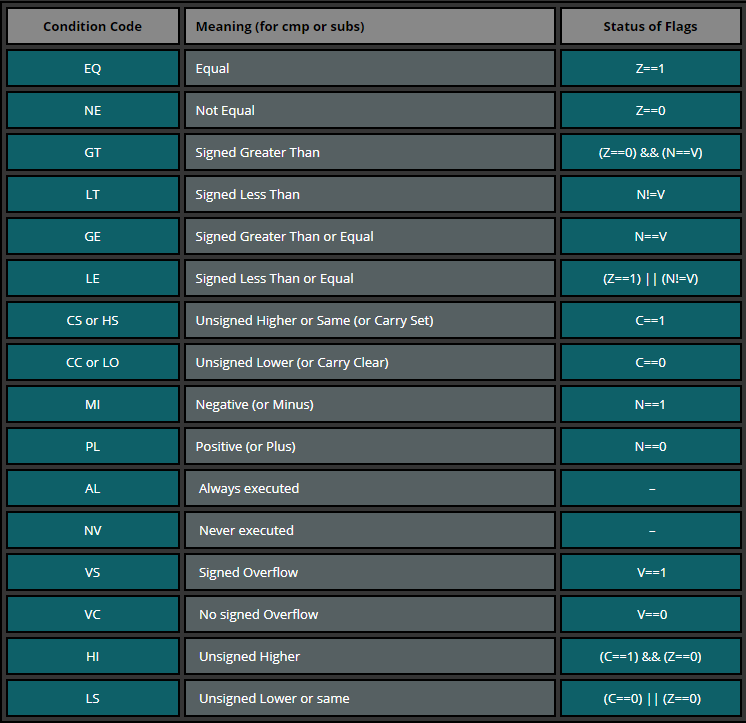
可以使用以下的例子:
1 | .global main |
7.1 Thumb 中的条件执行
在前面我们说过存在不同版本的Thumb的情况,具体来说,有允许条件执行的Thumb版本(Thumb-2)。某些ARM处理器的版本支持IT指令,该指令最多可以在Thumb状态下有条件的执行4条指令。
语法:IT {x {y {z}}} cond
cond规定了执行IT语句块里的第一条指令需要满足的条件x规定了执行的IT语句块中第二条指令需要满足的条件y规定了执行IT语句块里的第三条指令需要满足的条件z规定了执行IT语句块里的第四条指令需要满足的条件IT指令集的结构是: “IF-Then-(Else)”,它的语法结构由两个字母构成:
IT代表If-Then(下一条指令是条件指令)
TT代表If-Then-Then(接下来的两条指令是条件指令)
ITE代表 If-Then-Else(接下来的两条指令是条件指令)
ITTE代表 If-Then-Then-Else (接下来的三条指令是条件指令)
ITTEE代表 If-Then-Then-Else-Else (接下来的四条指令是条件指令)
IT块中的每条指令必须指定一个条件后缀,该条件后缀可以是相同的,也可以是在逻辑相反的。 这意味着,如果使用了ITE,第一和第二指令(If-Then)必须具有相同的条件后缀,而第三条指令(else语句)必须和前面两条语句逻辑相反。
1 | ITTE NE ; Next 3 instructions are conditional |
下面是与条件代码相反的内容
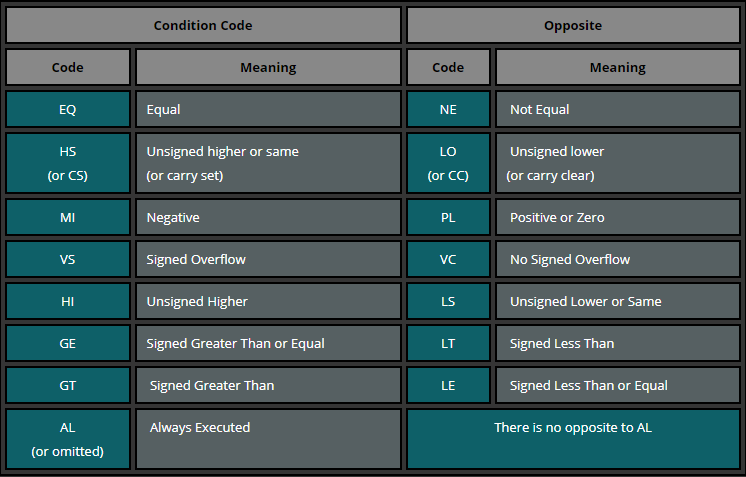
1 | .syntax unified @ this is important! |
.code32
示例代码以arm状态开始, 第一条指令将PC加1中指定的地址添加到R3,然后跳转到R3中的地址。 这将导致切换到Thumb状态,因为LSB(最低有效位)为1,因此没有4字节对齐。
.code 16
在Thumb状态下,我们首先将R0和 #10进行比较,结果是 N = 1,然后我们使用if-Than-else块,这个块会跳过 addeq指令,因为Z位并没有被设置,而addne将被执行,因为结果不等于 10
7.2 分支执行
分支 又称为跳转,使得我们可以跳转到另外一个代码段。当我们需要跳过或者重复代码块,到特定的位置的方法的时候,这将非常有用。这种情况下,最好的示例是IF语句或者一个循环,所以,首先来看一下IF语句:
1 | .global main |
这段代码判断哪一个数字更大, 然后将它作为返回值,伪C代码如下:
1 | int main() { |
现在使用条件指令和不使用条件指令下的循环:
1 | .global main |
伪C代码:
1 | int main() { |
7.3 B/BX/BLX
有三种类型的分支指令:
Branch(B)
- 简单的跳转进入一个函数
Vramch link (BL)
- 保存返回地址(PC+4)到LR,然后跳转进函数
- TIPS:ARM执行一条指令有三个步骤,取址,译码,执行,且当第一条指令取址完成之后,马上开始第二条指令取址,所以,当第一条指令执行的时候,PC已经指向了第三条指令
- 如果是使用了BL执行了正常的跳转,那么CPU会将返回地址存入LR中,即当前指令地址+4
- IRQ异常发生:异常发生在指令执行的时候,此时PC指向当前执行指令+8,然后将它存入LR中,所以恢复的时候需要-4以执行下面一条指令
- 未定义指令异常:发生在译码阶段,此时PC指向当前执行指令+4的位置,返回时不用计算
- 预取址指令:在执行阶段进入异常,所以PC指向当前执行指令地址+8,返回时需要-4
- 数据终止异常,在指令执行完毕之后产生,PC指向当前执行指令地址+12,恢复的时候需要-8
- 保存返回地址(PC+4)到LR,然后跳转进函数
Branch exchange (BX) and Branch link exchange (BLX)
- 和B/BL+交换指令集相同( ARM <-> Thumb )
- 需要用寄存器作为第一操作数:BX/BLX+具体的寄存器
BX/BLX用来从ARM指令集切换到Thumb指令集
1 | .text |
这里的技巧时获取当前PC的值,然后加1,将它存入一个寄存器,然后 分支(+交换)到这个寄存器。可以看到,加法指令简单的获取有效的PC地址(PC+8)然后加1。接下来,如果我们分支指令后面地址的最低有效位(LSB)是1 的时候,意味着地址不是4字节对齐的,将会发生状态转换。
7.4 条件分支指令
分支还可以有条件的执行,如果满足特定的条件,则跳到某一个函数,下面的例子:
1 | .text |
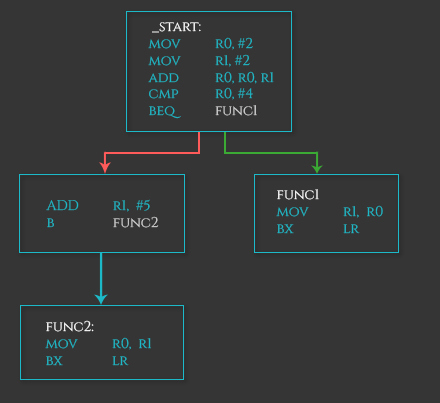
8 栈和函数
在这一部分中,我们将研究栈的进程的特殊存储区域
8.1 栈
一般来说,栈式程序,进程内的内存区域。创建进程的时候这部分的内存会被分配。我么能使用栈来存储临时数据,例如某些函数的局部变量,环境变量等,这些变量可以帮助我们在函数之间切换。我们使用PUSH,POP等指令来和栈交互,PUSH和POP是一系列其他的内存相关指令的总称的别名,而不是实际指令,但为了让事情变得简单,我们使用了PUSH和POP。
栈式可以使用不同的方式来实现的,首先,当我们说一个栈增长了,是指将一项(32位)数据放入了栈中,栈可能是从大到小递减,也可能是从小到大递增。下一个数据放在那个位置实际上是由SP指针所定义,确切的说,就是存储在SP寄存器中的内存地址。然后SP可能指向当前的最后一个地址,也可能指向下一个即将使用的地址。 如果SP当前指向堆栈中的最后一个项目(完整堆栈实现),SP将先减少(在堆栈降序排列的情况下)或增加(在栈升序排列的情况下),并且只有这么做后,项目才能被放置在堆栈中。如果SP当前指向栈中的下一个空白内存槽,则数据将首先被放置在这里,并且SP将被减少(降序堆栈)或增加(升序堆栈)。
- 向上生长:递增栈
- 栈顶指针指向最后一个有效数据项:满栈 满递增栈,使用LDMFA,STMFA等
- 栈顶指针指向下一个将要使用的空间:空栈 空递增栈,使用LDMEA,STMEA等
- 向下生长:递减栈
- 栈顶指针指向最后一个有效数据项:满栈 满递减栈,使用LDMFD,STMFD等
- 栈顶指针指向下一个将要使用的空间:空栈 空递减栈,使用LDMED,STMED等
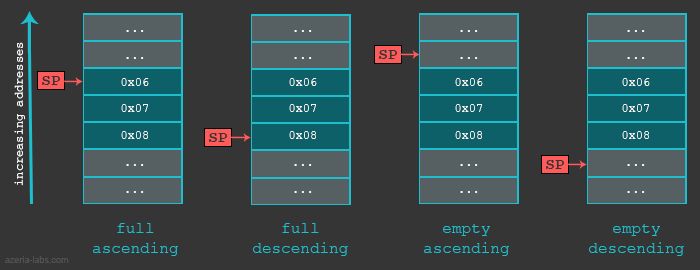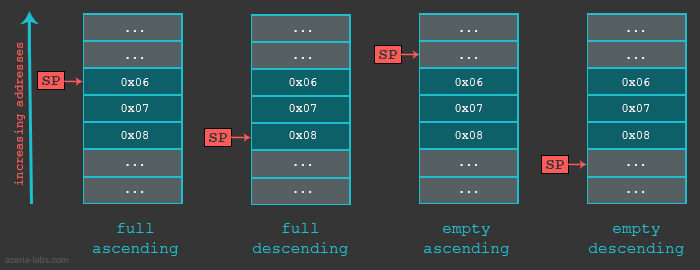
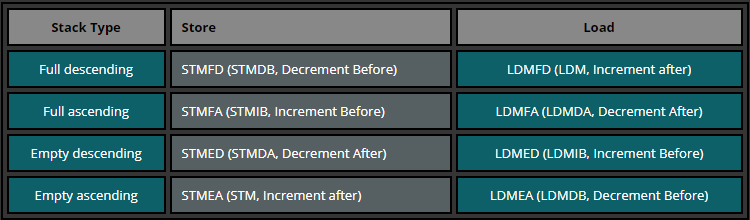
以下总结了不同堆栈实现方式,我们可以使用下表来描述在不同情况下,存储多个指令和载入多个指令在不同情形下是如何使用的。
当Rn == SP时使用外面的,否则使用括号里面的
1 | .global main |
我们将看到,函数利用堆栈来保存局部变量,保留寄存器状态等等。
为了使得所有的内容都井井有条,函数使用栈帧,栈中的一片本地化内存区域,专用于特定的函数。栈帧是在函数序言(函数开始的过程)下创建的,将帧指针FP 设定到栈的底部,然后为栈分配空间。一般函数的栈会包括:函数的返回地址, 之前的帧指针 , 需要保存的任何寄存器 , 函数参数(如果参数个数大于4),局部变量等。虽然栈的室内存储内容可能有所不同,但是上述内容是最常见的,然后,栈会在函数运行到结尾的时候被破坏。
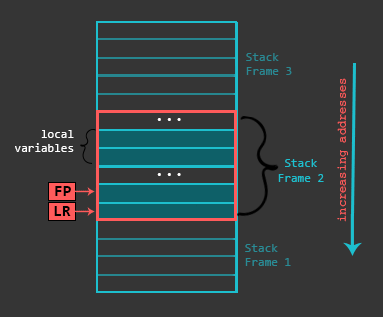
8.2 函数
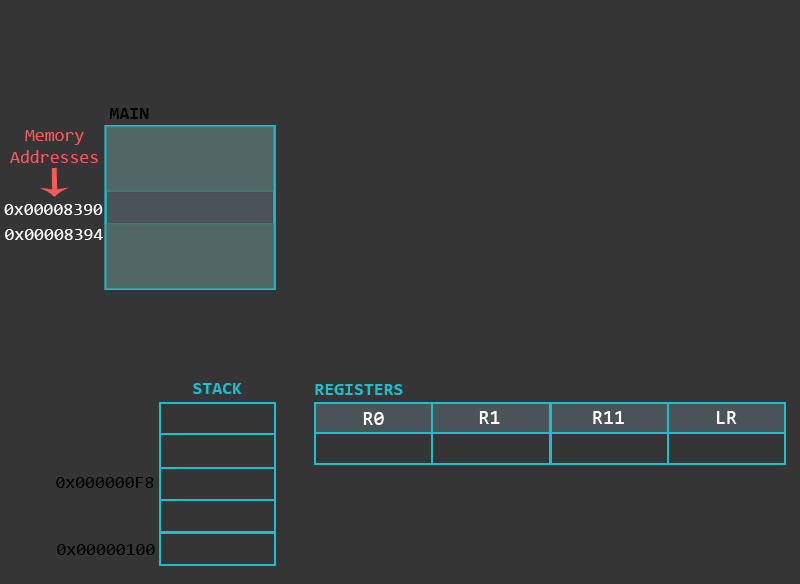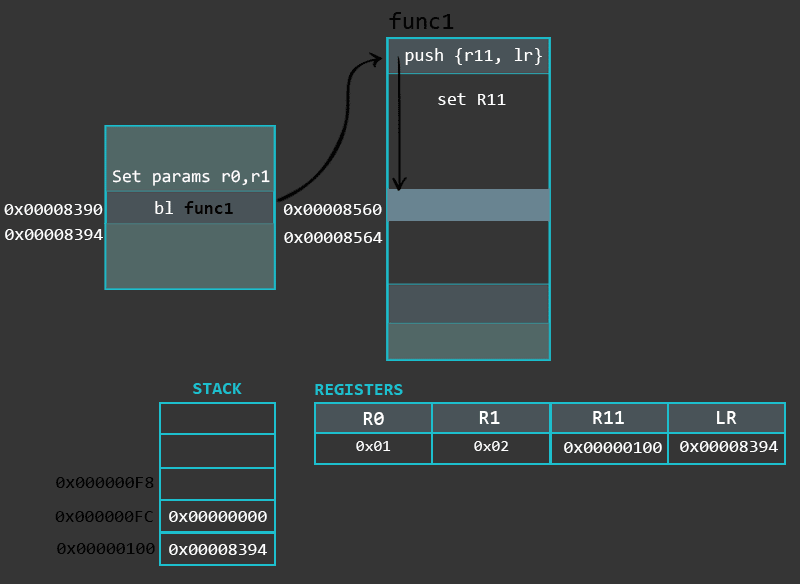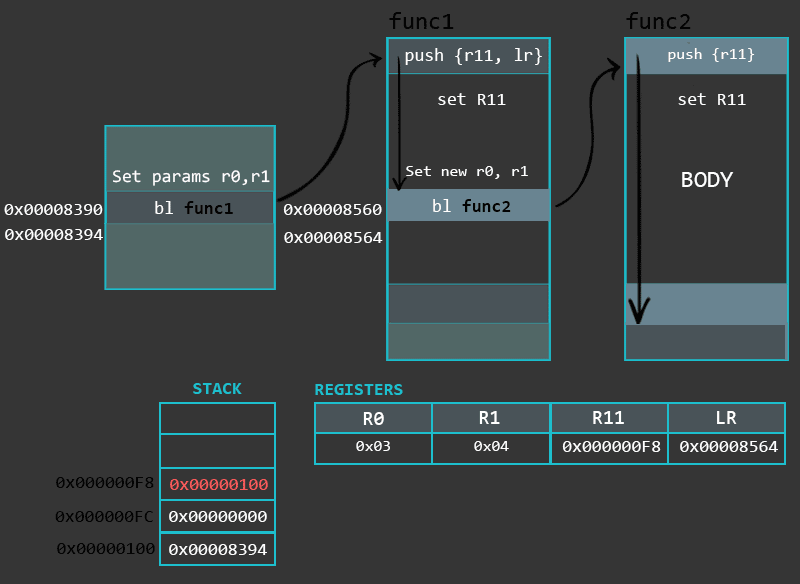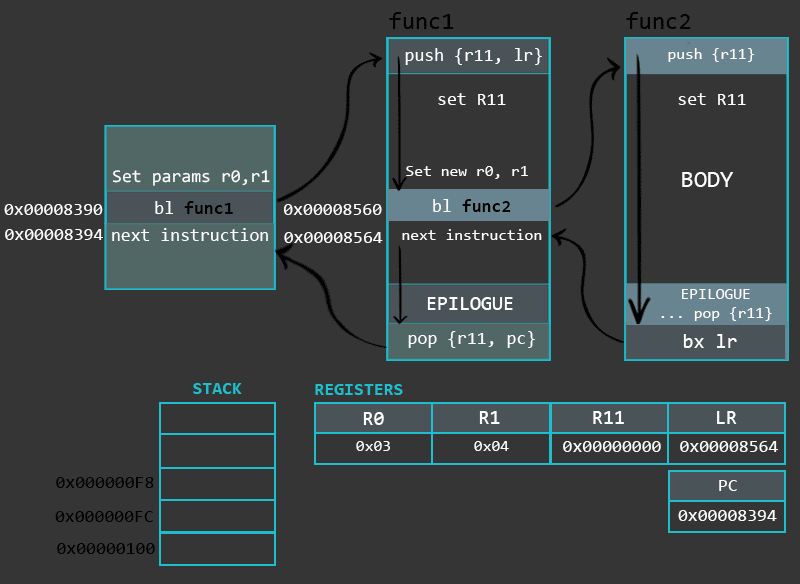
一个函数可以分为三个部分:
Prologue 序言
Body 函数主体
Epilogue 尾声
(序言)的目的是保存程序的先前状态(通过将LR和R11的值存储到堆栈上)并为函数的局部变量开辟堆栈空间。虽然序言的实现可能取决于所使用的编译器,但通常通过使用PUSH/ADD/SUB指令来完成。有这样一个例子:
1 | push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */ |
函数的主体部分通常负责执行某种特殊的和特定的任务。函数的这一部分可以包含多种指令、分支(跳转)到其他函数等。函数的函数主体部分的示例可以与以下几个指令一样简单:
1 | mov r0, #1 /* setting up local variables (a=1). This also serves as setting up the first parameter for the function max */ |
可以看到函数的参数也是通过寄存器传递的,在某些情况下,如果我们要传递的参数大于4个 的时候,将会使用栈来存储其余的参数。函数的结果将通过r0返回,因此无论函数max的最大结果是什么,我们应该在函数返回之后立即从r0中取出它,需要注意的是,在某些情况下,结果可能是64位,而寄存器大小是32位,这个时候就需要R0和R1一起使用返回一个64位的结果。
函数的最后一部分,尾声(epilogue),用来将程序恢复到初始状态(调用函数之前的状态), 使得它可以从函数离开的位置继续执行,因此我们需要重新调整栈指针, 通过使用帧指针寄存器(R11)作为参考并执行加法或子运算来完成此操作。 一旦我们重新调整了堆栈指针,就可以通过将它们从堆栈中弹出到各自的寄存器中来恢复先前保存的寄存器值。 POP指令可能是结尾部分的最后指令,这取决于函数的类型 。但是,在恢复寄存器值之后,我们可能会使用BX指令来离开函数。尾声(Epilogue)的一个例子是这样的:
1 | sub sp, r11, #0 /* Start of the epilogue. Readjusting the Stack Pointer */ |
现在可以知道
- 函数序言部分构建了函数的运行环境
- 函数主体部分实现函数的逻辑并将返回值存储进R0
- 尾声部分恢复了函数被调用之前的状态并继续运行
另一个关键理解函数的关键点是他们的类型:叶和非叶:
叶子函数是一种不会从自身调用/分支到另一个函数的函数。
非叶子函数是一种函数,除了自身的逻辑之外,它还会调用/分支到另一个函数。
这两种函数的功能是类似的,但是还是又一些区别的,使用以下代码分析:
1 | .global main |
main 函数调用的max函数,而max函数没有调用其他的函数,所以main函数是一个非叶函数而max函数是一个叶函数。
叶函数和非叶函数序言和尾声的实现方式不同:
1 | /* A prologue of a non-leaf function */ |
非叶函数的序言需要将更多的寄存器保存在堆栈里。背后的原因在于,由于非叶函数的天然属性,在执行这样的函数期间LR被修改了,因此需要保存该寄存器的值,以便以后能够恢复。一般来说,如果必要的话,序言可以保存更多的寄存器。
1 | /* An epilogue of a leaf function */ |
叶函数会跳转到存储在LR寄存器中的地址,而非叶函数直接POP地址到的PC寄存器。
最后需要理解的是BL和BXL指令的使用, 我们使用BL指令分支到叶函数。我们使用函数的标签作为参数来启动分支。在编译过程中,标签被替换为内存地址。在跳转到该位置之前,下一条指令的地址被保存(链接)到LR寄存器,这样我们就可以返回到函数max结束时离开的位置。
BX指令用于从叶函数退出,以LR寄存器作为参数,在之前提到过,在跳转到函数max之前,BL指令将函数main的下一条指令的地址保存到LR寄存器中。 因为不希望叶子函数在执行的过程中更改了LR寄存器的值。这个寄存器闲杂被用来返回main函数。在上一章里面说过, BX指令可以在ARM / Thumb模式之间进行切换。 在这种情况下,可以通过检查LR寄存器的最后一位来完成:如果该位设置为1,CPU会将模式更改(或保持)为Thumb模式, 如果设置为0,则模式将更改(或保留为ARM)。这是一个很好的设计功能,它允许从不同的模式调用函数。